ThingPark Enterprise
GUI access issues
-
If it's the first install, validate that all deployments and statefulsets are all in the
READYstate:kubectl get sts -n $NAMESPACE -l 'app.kubernetes.io/instance in (tpe,tpe-data,mongo-replicaset,kafka-cluster)'
kubectl get deploy -n $NAMESPACE -l 'app.kubernetes.io/instance in (tpe)' -
Check that the Load balancer is successfully provisioned and has an external IP:
$ kubectl get svc tpe-controllers-ingress-nginx-controller
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tpe-controllers-ingress-nginx-controller LoadBalancer 172.21.94.159 20.103.180.150 80:31203/TCP,443:31100/TCP,2022:32058/TCP,3001:30854/TCP,3002:30435/TCP,3101:30712/TCP 3d23h -
If you stay on page "Loading... please wait" when you try to access the TPE Portal GUI, the TLS certificate for HTTP traffic may have expired. In this case, you must generate a new certificate and update the Helm tpe release with it.
-
You can retrieve ingress access logs in following manner:
kubectl logs -l app.kubernetes.io/name=ingress-nginx -f
ThingPark Enterprise upgrade issues
The last upgrade failure is stored in following configmap:
kubectl get cm thingpark-enterprise-upgrade -o jsonpath='{.data}'
Pre install job issue
If pre upgrade tasks fail at upgrade time, you can get information about issue in the following way:
-
Start by ensuring that it is this job that is not completed
$ kubectl get job/thingpark-enterprise-pre-upgrade
NAME COMPLETIONS DURATION AGE
thingpark-enterprise-pre-upgrade 0/1 103s 3m20s -
Get job logs using the following command. This log trace can be provided to support when at least 1 task failed
$ kubectl logs job/thingpark-enterprise-pre-upgrade
...
- Play recap -
localhost : ok=97 changed=58 unreachable=0 failed=1 rescued=0 ignored=0
2022-03-21 17:00:39,644 p=1 u=root n=ansible | localhost : ok=97 changed=58 unreachable=0 failed=1 rescued=0 ignored=0
Playbook run took 0 days, 0 hours, 1 minutes, 39 seconds
2022-03-21 17:00:39,644 p=1 u=root n=ansible | Playbook run took 0 days, 0 hours, 1 minutes, 39 seconds
Post install job Issues
Information about a post upgrade failure can also be retrieved in same manner:
$ kubectl get job/thingpark-enterprise-post-upgrade
NAME COMPLETIONS DURATION AGE
thingpark-enterprise-post-upgrade 0/1 85s 2d15h
$ kubectl logs job/thingpark-enterprise-post-upgrade
...
- Play recap -
localhost : ok=6 changed=1 unreachable=0 failed=1 rescued=0 ignored=0
2022-03-21 17:03:08,661 p=1 u=root n=ansible | localhost : ok=6 changed=1 unreachable=0 failed=1 rescued=0 ignored=0
Playbook run took 0 days, 0 hours, 0 minutes, 55 seconds
2022-03-21 17:03:08,662 p=1 u=root n=ansible | Playbook run took 0 days, 0 hours, 0 minutes, 55 seconds
Base Station connection issues
Test if mandatory processes are running
Test if mandatory processes are running the via "Troubleshooting/CPU / Memory / Processes" menu:

"lrr.x" application is mandatory (eventually try to reboot the GW if you do not have it).
From ThingPark Enterprise, using k8s api
Check BS certificates availability
Certificates are stored in the Mongo database. Using Kubernetes api, connect to Mongo db:
kubectl exec -n $NAMESPACE -it mongo-replicaset-rs0-0 -c mongod -- mongo -u key-installer -p <password> mongodb://mongo-replicaset-rs0
Select the "key-installer" database:
rs0:PRIMARY> use key-installer
switched to db key-installer
From "archives" collection, check certificate package availability based on your LRR UUID.
Example below with LRR UID "123456-46584254C0001340".
rs0:PRIMARY> db.archives.find({"lrrUUID": "123456-46584254C0001340"});
If the certificates' package has not been created, try to regenerate the certificate from the TPE GUI.
Check connection from server side
Connect to LRC CLI via telnet (key is 123):
kubectl exec -n $NAMESPACE -it lrc-0 -c lrc -- telnet 0 2009
Check all GW currently connected with LRC:
>> ls
Check one GW connection based on its LRR UUID:
>> ls <LRR UUID>
From ThingPark Enterprise, using GUI
When flows between the BS and TPE are all OK, the BS State will change from "Initialization" to "Connection error" for around 10 to 15 min during the first connection.
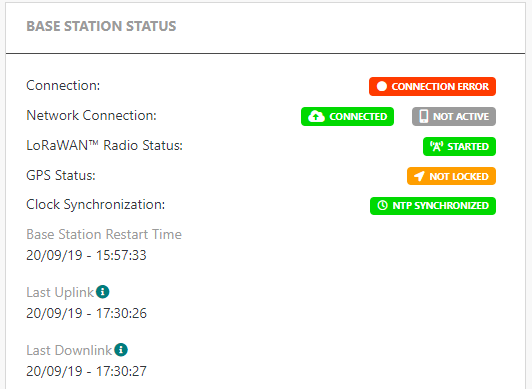
When the TPE receives the first report from the BS, the status will become "Active".
- If the BS has been deleted and recreated in TPE, the state "Initialization" may persist. In this case, the BS needs to be re-flashed.
- For BS not connected with TLS, the state "Connection error" may persist. In this case you need to connect to the BS and update the lrr configuration with the IP (X.X.X.X) of the ThingPark Enterprise instead of the hostname (hostname.domaine).
Base Station or Device provisioning issues
Target manufacturer/model is missing
Check that you have downloaded the most recent Device and Base Station catalog in Manage > Operating Management.
If the catalog cannot be updated, you may check and set your proxy settings in your Helm custom values configuration file.
Also check that you have set the correct ISM band corresponding to your device or Base Station.
If you still have issues with catalogs installation, you may manually reinstall them.
Device cannot join
- Check that the associated device profile corresponds to your device and update it accordingly.
- Check that you have set the correct ISM band corresponding to your device or Base Station.
Application Server issues
Uplink packets not received by the AS
If you have an HTTPS Application Server with self-signed certificate and
your device uplinks are not received by the AS, check the parameter global.asSecurity
in your Helm custom values configuration file.
Devices issues
Activate LRC traces for a given device
When a specific device or group of devices experiences connectivity issues that require in-depth troubleshooting, you can increase the LRC trace level to debug and resolve the problems effectively.
- Connect to LRC CLI via Telnet (key is 123):
kubectl exec -n $NAMESPACE -it lrc-0 -c lrc -- telnet 0 2009
- Add the device's devEUI to the list of devices with an increased trace level:
>> traceadd <devEUI>
For example:
>> traceadd 1000000000000003
You can add up to 10 devices to the list.
-
View the list of devices with an increased trace level:
>> tracelistSample command output:
>> tracelist
1000000000000003 1000000000000005 -
To disconnect from the LRC CLI, simply enter the
exitcommand. -
To access device logs, retrieve the logs from the LRC container:
kubectl logs -n $NAMESPACE lrc-0
- To remove a device from the list of devices with an increased trace level, repeat step 1, and then use the following command:
>> tracermv <devEUI>
For example :
>> tracermv 1000000000000003
To remove all the devices from the list, you can use the following command:
>> tracermv *
Finally, repeat step 4 to disconnect.