ThingPark Enterprise
Problèmes d'accès à l'IHM
-
Si c'est la première installation, validez que tous les déploiements et statefulsets sont tous dans l'état
READY:kubectl get sts -n $NAMESPACE -l 'app.kubernetes.io/instance in (tpe,tpe-data,mongo-replicaset,kafka-cluster)'
kubectl get deploy -n $NAMESPACE -l 'app.kubernetes.io/instance in (tpe)' -
Vérifiez que le Load balancer est bien provisionné et dispose d'une IP externe :
$ kubectl get svc tpe-controllers-ingress-nginx-controller
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tpe-controllers-ingress-nginx-controller LoadBalancer 172.21.94.159 20.103.180.150 80:31203/TCP,443:31100/TCP,2022:32058/TCP,3001:30854/TCP,3002:30435/TCP,3101:30712/TCP 3d23h -
Si vous restez sur la page "Chargement... attendez" lorsque vous essayez d'accéder au portail GUI TPE, le certificat TLS pour le trafic HTTP peut avoir expiré. Dans ce cas, vous devez générer un nouveau certificat et mettre à jour la release Helm tpe avec celui-ci.
-
Vous pouvez récupérer les journaux d'accès d'entrée de la manière suivante :
kubectl logs -l app.kubernetes.io/name=ingress-nginx -f
Problèmes de mise à jour de ThingPark Enterprise
La dernière défaillance de mise à jour est stockée dans le configmap suivant :
kubectl get cm thingpark-enterprise-upgrade -o jsonpath='{.data}'
Problème de pré-installation
Si les tâches de pré-mise à jour échouent lors de la mise à jour, vous pouvez obtenir des informations sur le problème de la manière suivante :
-
Assurez-vous d'abord que c'est bien ce travail qui n'est pas terminé
$ kubectl get job/thingpark-enterprise-pre-upgrade
NAME COMPLETIONS DURATION AGE
thingpark-enterprise-pre-upgrade 0/1 103s 3m20s -
Récupérez les journaux de travail en utilisant la commande suivante. Cette trace de journal peut être fournie à l'assistance lorsque au moins 1 tâche échoue
$ kubectl logs job/thingpark-enterprise-pre-upgrade
...
- Play recap -
localhost : ok=97 changed=58 unreachable=0 failed=1 rescued=0 ignored=0
2022-03-21 17:00:39,644 p=1 u=root n=ansible | localhost : ok=97 changed=58 unreachable=0 failed=1 rescued=0 ignored=0
Playbook run took 0 days, 0 hours, 1 minutes, 39 seconds
2022-03-21 17:00:39,644 p=1 u=root n=ansible | Playbook run took 0 days, 0 hours, 1 minutes, 39 seconds
Problèmes de travail post-installation
Les informations sur un échec de post-mise à jour peuvent également être récupérées de la même manière :
$ kubectl get job/thingpark-enterprise-post-upgrade
NAME COMPLETIONS DURATION AGE
thingpark-enterprise-post-upgrade 0/1 85s 2d15h
$ kubectl logs job/thingpark-enterprise-post-upgrade
...
- Play recap -
localhost : ok=6 changed=1 unreachable=0 failed=1 rescued=0 ignored=0
2022-03-21 17:03:08,661 p=1 u=root n=ansible | localhost : ok=6 changed=1 unreachable=0 failed=1 rescued=0 ignored=0
Playbook run took 0 days, 0 hours, 0 minutes, 55 seconds
2022-03-21 17:03:08,662 p=1 u=root n=ansible | Playbook run took 0 days, 0 hours, 0 minutes, 55 seconds
Problèmes de connexion à la passerelle
Testez si les processus obligatoires sont en cours d'exécution
Testez si les processus obligatoires fonctionnent via le menu "Dépannage/CPU/Mémoire/Processus" :

L'application "lrr.x" est essentielle (essayez éventuellement de redémarrer la passerelle si vous ne l'avez pas).
Depuis ThingPark Enterprise, utilisant l'api k8s
Vérifiez la disponibilité des certificats BS
Les certificats sont stockés dans la base de données Mongo. En utilisant l'api Kubernetes, connectez-vous à Mongo db :
kubectl exec -n $NAMESPACE -it mongo-replicaset-rs0-0 -c mongod -- mongosh -u key-installer -p <password> mongodb://mongo-replicaset-rs0
Sélectionnez la base de données "key-installer" :
rs0:PRIMARY> use key-installer
switched to db key-installer
Dans la collection "archives", vérifiez la disponibilité du paquet de certificat basé sur votre LRR UUID.
Exemple ci-dessous avec LRR UID "123456-46584254C0001340".
rs0:PRIMARY> db.archives.find({"lrrUUID": "123456-46584254C0001340"});
Si le paquet de certificats n'a pas été créé, essayez de régénérer le certificat à partir du GUI TPE.
Vérifiez la connexion côté serveur
Connectez-vous au LRC CLI via telnet (clé est 123):
kubectl exec -n $NAMESPACE -it lrc-0 -c lrc -- telnet 0 2009
Vérifiez toutes les passerelles actuellement connectées au LRC :
>> ls
Vérifiez une connexion de la passerelle en fonction de son LRR UUID :
>> ls <LRR UUID>
Depuis ThingPark Enterprise, utilisant GUI
Lorsque les flux entre la passerelle et TPE sont tous corrects, l'état de la passerelle passera de "Initialisation" à "Erreur de connexion" pendant environ 10 à 15 minutes lors de la première connexion.
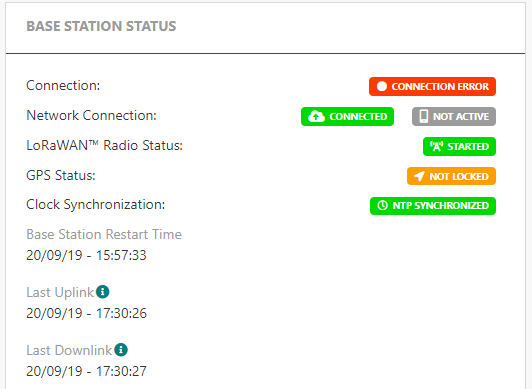
Lorsque le TPE reçoit le premier rapport de la passerelle, le statut deviendra "Actif".
- Si la passerelle a été supprimée et recréée dans TPE, l'état "Initialisation" peut persister. Dans ce cas, la passerelle doit être réinitialisée.
- Pour la passerelle non connectée avec TLS, l'état "Erreur de connexion" peut persister. Dans ce cas, vous devez vous connecter à la passerelle et mettre à jour la configuration lrr avec l'IP (X.X.X.X) de ThingPark Enterprise au lieu du nom d'hôte (nomd'hôte.domaine).
Problèmes d'approvisionnement de passerelle ou capteur
Fabricant/modèle cible manquant
Vérifiez que vous avez téléchargé le catalogue de Capteur et de Passerelle le plus récent dans Gérer > Gestion des opérations.
Si le catalogue ne peut pas être mis à jour, vous pourriez vérifier et définir vos paramètres de proxy dans votre fichier de configuration des valeurs personnalisées Helm.
Vérifiez également que vous avez défini la bande ISM correcte correspondant à votre capteur ou passerelle.
Si vous rencontrez toujours des problèmes d'installation des catalogues, vous pouvez les réinstaller manuellement.
Le capteur ne peut pas rejoindre
- Vérifiez que le profil du capteur associé correspond à votre capteur et mettez-le à jour en conséquence.
- Assurez-vous que vous avez défini la bande ISM correcte correspondant à votre capteur ou passerelle.
Problèmes du serveur d'application
Les paquets uplink ne sont pas reçus par le Serveur d'application
Si vous avez un serveur d'application HTTPS avec certificat auto-signé et
que vos montées de données du capteur ne sont pas reçues par l'AS, vérifiez le paramètre global.asSecurity
dans votre fichier de configuration des valeurs personnalisées Helm.
Problèmes des capteurs
Activer les traces LRC pour un capteur donné
Lorsqu'un capteur spécifique ou un groupe de capteurs rencontre des problèmes de connectivité qui nécessitent un dépannage approfondi, vous pouvez augmenter le niveau de trace LRC pour débugger et résoudre les problèmes efficacement.
- Connectez-vous au LRC CLI via Telnet (clé est 123):
kubectl exec -n $NAMESPACE -it lrc-0 -c lrc -- telnet 0 2009
- Ajoutez le devEUI du capteur à la liste des capteurs avec un niveau de trace augmenté :
>> traceadd <devEUI>
Par exemple :
>> traceadd 1000000000000003
Vous pouvez ajouter jusqu'à 10 capteurs à la liste.
-
Afficher la liste des capteurs avec un niveau de trace augmenté :
>> tracelistSortie de commande exemple :
>> tracelist
1000000000000003 1000000000000005 -
Pour vous déconnecter du LRC CLI, entrez simplement la commande
exit. -
Pour accéder aux journaux du capteur, récupérez les journaux à partir du conteneur LRC :
kubectl logs -n $NAMESPACE lrc-0
- Pour supprimer un capteur de la liste des capteurs avec un niveau de trace augmenté, répétez l'étape 1, puis utilisez la commande suivante :
>> tracermv <devEUI>
Par exemple :
>> tracermv 1000000000000003
Pour supprimer tous les capteurs de la liste, vous pouvez utiliser la commande suivante :
>> tracermv *
Enfin, répétez l'étape 4 pour vous déconnecter.