Problèmes d'installation et de mise à niveau TPE
Cockpit est inaccessible
SYMPTÔME : Après avoir personnalisé le certificat Cockpit lors de la première installation ou en modifiant la configuration de l'infrastructure, Cockpit est inaccessible ("CONNECTION_REFUSED").
SOLUTION :
-
Vérifiez l'état du service système systemd de Cockpit.
systemctl status cockpit -
Si vous voyez l'erreur
Le certificat et la clé donnée ne correspondent pas, exécutez les commandes suivantes pour nettoyer le certificat Cockpit, puis redéployez le cluster en utilisant le module Cockpit du Service TPE avec le certificat et la clé privée corrects.sudo rm /etc/cockpit/ws-certs.d/cockpit.cert
sudo rm /etc/cockpit/ws-certs.d/cockpit.key
systemctl restart cockpit
GUI est inaccessible
SYMPTÔME : Après une première installation, le navigateur n'arrive pas à charger la page ("Chargement... veuillez patienter") ou affiche une erreur de certificat.
SOLUTION :
- Vérifiez le système de surveillance (Pour plus d'informations, voir Lister les Conteneurs et Vérification de l'état).
- Si des erreurs surviennent lors de la tentative d'accès au GUI du portail TPE après l'installation de TPE, essayez de reconfigurer le nom d'hôte du système TPE à "actility.local". Enregistrez & appliquez les modifications et essayez d'accéder au GUI du portail TPE en utilisant
https://enterprise.actility.local/tpe. Si cela fonctionne, votre certificat est incorrect. - Si vous restez sur la page "Chargement... attendez" lorsque vous essayez d'accéder au GUI du portail TPE, le certificat TLS pour le trafic HTTP est peut-être expiré. Si le certificat TLS est expiré, sur Cockpit de TPE, un message d'erreur s'affiche en haut de la "page de configuration TPE"
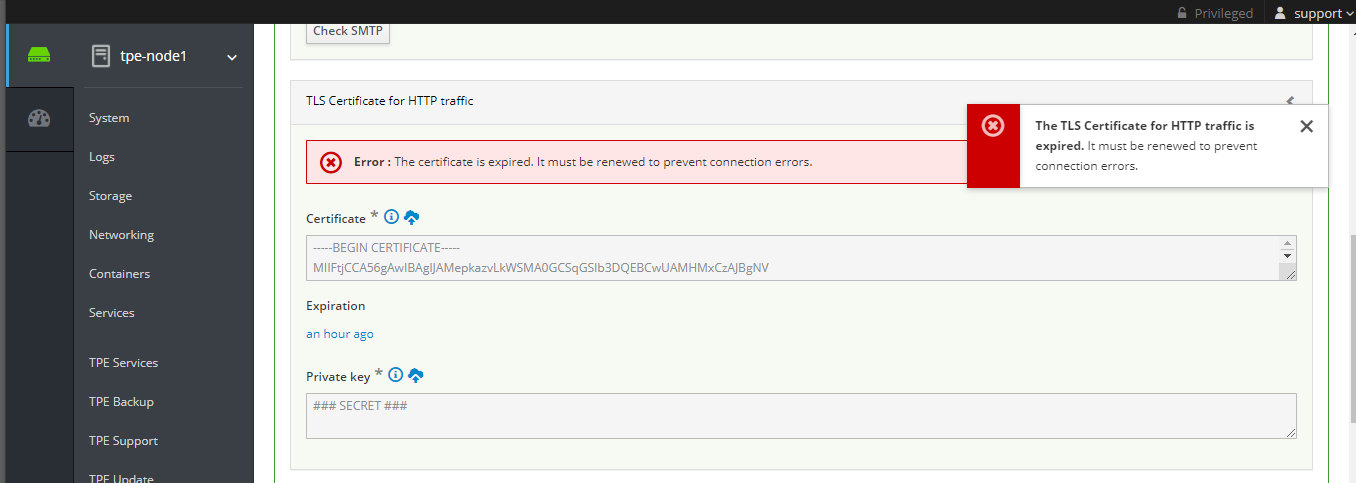
Dans ce cas, vous devez générer un nouveau certificat et le télécharger.
Le GUI affiche des messages d'erreur inattendus
SYMPTÔME : Après une mise à jour HA, le GUI affiche des erreurs de connexion (popup affichant "Une erreur inattendue s'est produite", "Erreur inconnue").
SOLUTION :
- Déconnectez-vous puis reconnectez-vous au GUI (cela peut nécessiter jusqu'à 10 itérations de déconnexion/reconnexion pour vider la piscine de connexions SQL),
- Si le problème persiste, redémarrez les deux conteneurs proxy SQL et réessayez de vous connecter au GUI de TPE.
La mise à jour de YUM échoue
SYMPTÔME : La procédure de mise à jour TPE échoue avec l'erreur suivante :
There are unfinished transactions remaining. You might consider running yum-complete-transaction, or "yum-complete-transaction --cleanup-only" and "yum history redo last", first to finish them. If those don't work you'll have to try removing/installing packages by hand (maybe package-cleanup can help).
SOLUTION :
-
Exécutez la commande suivante via ssh :
sudo yum-complete-transaction -
Ensuite, réessayez la procédure de mise à jour TPE.
La procédure de mise à jour échoue avec le message "ansible_memtotal_mb is undefined"
SYMPTÔME : La procédure de mise à jour TPE échoue avec l'erreur suivante :
tpe_node1 failed | msg: The conditional check 'ansible_memtotal_mb < max_xs_host_memory_size_mb' failed. The error was: error while evaluating conditional (ansible_memtotal_mb < max_xs_host_memory_size_mb): 'ansible_memtotal_mb' is undefined^M
SOLUTION :
Réessayez la procédure de mise à jour TPE.
La procédure de mise à jour échoue avec le message "Pas assez d'espace disque pour effectuer la mise à niveau"
SYMPTÔME : La procédure de mise à jour TPE échoue avec l'erreur suivante :
NOTE: There is not enough disk space to perform the upgrade (at least 10GB required).
SOLUTION :
- Supprimez les images de conteneurs inutiles, voici la procédure
- Libérez de l'espace disque
Le service actility_post-upgrade reste dans un état défaillant après le redémarrage
SYMPTÔME : Après un redémarrage de l'instance TPE, le service actility_post-upgrade reste dans un état défaillant dans Cockpit. Cela est dû au fait que le service post-upgrade n'a pas été redémarré automatiquement après le redémarrage.
SOLUTION :
La solution consiste à redéployer manuellement le service actility_post-upgrade. Pour cela :
- Connectez-vous à Cockpit
- Allez dans le module Services TPE
- Sous le répertoire "autres", pour le service "actility_post-upgrade", cliquez sur le bouton "Actions" puis sur "Redéployer"
L'approvisionnement des images de conteneur a échoué
SYMPTÔME : Lors d'une installation, d'une mise à niveau ou d'un redéploiement de cluster, l'approvisionnement des images de conteneur peut échouer et la procédure (installation, mise à niveau ou redéploiement) s'arrête.
tpe_node1 -> localhost failed | item: {u'key': u'mongo', u'value': {u'image': u'tpe/mongo', u'version': u'5.2.0-4'}} | msg: Error pushing image registry1.actility.local:5000/tpe/mongo: dial tcp X.X.X.X:5000: connect: no route to host
tpe_node2 -> localhost failed | item: {u'key': u'twa_dev', u'value': {u'image': u'tpe/twa-dev', u'version': u'7.12.6-1'}} | msg: Error pushing image registry2.actility.local:5000/tpe/twa-dev: UnixHTTPConnectionPool(host='localhost', port=None): Read timed out.
Plusieurs raisons peuvent expliquer ce problème :
- problème de connexion réseau au dépôt TPE
- instabilité du registre local des images de conteneur
SOLUTION :
La solution est de redémarrer la procédure (installation, mise à niveau, redéploiement).
Échec du nettoyage des images de conteneur
SYMPTÔME : Lors d'une mise à niveau, le nettoyage des images de conteneur peut échouer avec l'erreur :
An error occurs during container images cleaning.
Comme cela n'est pas bloquant, la mise à niveau continuera mais les images de conteneur non nettoyées prendront de la place sur le disque.
SOLUTION :
Une fois la mise à niveau terminée, exécutez le script suivant pour nettoyer les images de conteneur :
/usr/bin/tpe-cleanup-container-images
Problème de configuration RF Region pour les passerelles Tektelic Kona Mega
SYMPTÔME : Après une mise à niveau auto-hébergée en 7.3.4, les passerelles Tektelic Kona Mega échouent à récupérer leur paquet RF Region pour les configurations radio suivantes :
- Passerelles configurées avec 2 antennes et plus de 8 canaux
- Passerelles configurées avec 1 antenne et plus de 16 canaux
SOLUTION : Exécutez la procédure suivante sur node1 et node2 pour un TPE OCP HA.
-
Connectez le nœud avec le compte SUPPORT, par exemple en utilisant le Terminal accessible depuis Cockpit.
-
Démarrez un bash sur le conteneur lrc :
docker exec -it $(docker ps -q -f "name=actility_lrc1") bashREMARQUE : Utilisez
actility_lrc1pour node1 etactility_lrc2pour node2 -
Régénérez le tarball RF_Region pour toutes les RF regions (cela prend 1 ou 2 minutes) :
for file in $(find /home/actility/FDB_lora/RFRegion/ ! -name '*DEFAULT-RFREGION-TEMPLATE' -type f | xargs -n 1 basename);do /home/actility/rfregtool/shells/dnrfregionid.sh -d /var/ftp/ -g $file; done
Ensuite, exécutez la procédure de vérification suivante :
-
Accédez au dossier FTP du conteneur LRC :
cd /var/ftp/ -
Vérifiez que deux TARBALL ont été générés pour US 72 canaux :
ls *US*72*b1_v2.tar.gzLa commande doit retourner deux fichiers TARBALL.
Le conteneur mongo_node3 ne peut pas démarrer (erreur featureCompatibilityVersion)
Si le conteneur mongo-node3 ne peut pas démarrer (erreur featureCompatibilityVersion) et génère cette erreur :
{"t":{"$date":"2025-09-04T08:02:46.414+00:00"},"s":"I", "c":"REPL", "id":5853300, "ctx":"initandlisten","msg":"current featureCompatibilityVersion value","attr":{"featureCompatibilityVersion":"unset","context":"startup"}}
{"t":{"$date":"2025-09-04T08:02:46.414+00:00"},"s":"I", "c":"STORAGE", "id":5071100, "ctx":"initandlisten","msg":"Clearing temp directory"}
{"t":{"$date":"2025-09-04T08:02:46.418+00:00"},"s":"F", "c":"COMMAND", "id":40652, "ctx":"initandlisten","msg":"Unable to start up mongod due to missing featureCompatibilityVersion document. Please run with --repair to restore the document."}
Exécutez la procédure suivante sur node3 pour un TPE OCP HA.
-
Connectez-vous à node3 avec le compte Support en utilisant le Terminal accessible depuis Cockpit.
-
Arrêtez le mongo_node3, nettoyez les données locales, puis redémarrez le mongo_node3
docker service scale actility_mongo_node3=0
docker volume rm actility_tpe-data-mongo
docker service scale actility_mongo_node3=1
Problème de résolution DNS interne
SYMPTÔME : Si, après un redémarrage, le service hyper-scheduler est UP mais l'alias DNS actility_hyper-scheduler ne peut pas être résolu, vous pouvez voir une erreur similaire à :
stdout : 2025-07-24T07:22:37.421545910Z Unable to reach scheduler service: 'Get "http://actility_hyper-scheduler:8080/services/actility_mongo_node1/allowedToStart": dial tcp: lookup actility_hyper-scheduler on 127.0.0.11:53: no such host'
Action : Redémarrez le service actility_hyper-scheduler en utilisant Cockpit.
SOLUTION :
La solution consiste à redéployer manuellement le service actility_hyper-scheduler. Pour cela :
- Connectez-vous à Cockpit
- Allez dans le module Services TPE
- Dans le répertoire "others", pour le service "actility_hyper-scheduler", cliquez sur le bouton "Actions" puis sur "Redéployer"